分散式雜湊表(英語:Distributed Hash Table,簡稱DHT)是分散式計算系統中的一類,用來將一個關鍵值(key)的集合分散到所有在分散式系統中的節點,並且可以有效地將訊息轉送到唯一一個擁有查詢者提供的關鍵值的節點(Peers)。這裡的節點類似雜湊表中的儲存位置。分散式雜湊表通常是為了擁有極大節點數量的系統,而且在系統的節點常常會加入或離開(例如網路斷線)而設計的。在一個結構性的延展網路(overlay network)中,參加的節點需要與系統中一小部份的節點溝通,這也需要使用分散式雜湊表。分散式雜湊表可以用以建立更複雜的服務,例如分散式檔案系統、點對點技術檔案分享系統、合作的網頁快取、多點傳輸、任意點傳輸(anycast)、網域名稱系統以及即時通訊等。
發展背景
研究分散式雜湊表的主要動機是為了開發點對點系統,像是Napster、Gnutella及Freenet。這些系統得益於使用分散在網際網路上的各項資源以提供實用的應用,特別在頻寬及硬碟儲存空間上,他們所提供的檔案分享功能因此得到最大的好處。
這些系統使用不同的方法來解決如何找到擁有某資料的節點的問題。Napster 使用中央的索引伺服器:每個節點加入網路的同時,會將他們所擁有的檔案列表傳送給伺服器,這使得伺服器可以進行搜尋並將結果回傳給進行查詢的節點。但中央 索引伺服器讓整個系統易受攻擊,且可能造成法律問題。於是,Gnutella 和相似的網路改用大量查詢模式(flooding query model):每次搜尋都會把查詢訊息廣播給網路上的所有節點。雖然這個方式能夠防止單點故障(single point of failure),但比起 Napster 來說卻極沒效率。
最後,Freenet 使用了完全分散式的系統,但它建置了一套使用經驗法則的基於關鍵值的轉送方法(key based routing)。在這個方法中,每個檔案與一個關鍵值相結合,而擁有相似關鍵值的檔案會傾向被相似的節點構成的集合所保管。於是查詢訊息就可以根據它所提供的關鍵值被轉送到該集合,而不需要經過所有的節點。然而,Freenet 並不保證存在網路上的資料在查詢時一定會被找到。
分散式雜湊表為了達到 Gnutella 與 Freenet 的分散性(decentralization)以及 Napster 的效率與正確結果,使用了較為結構化的基於關鍵值的轉送方法。不過分散式雜湊表也有個 Freenet 有的缺點,就是只能作精確搜尋,而不能只提供部份的關鍵字;但這個功能可以在分散式雜湊表的上層實做。
最初的四項分散式雜湊表技術——內容可定址網路(Content addressable network,CAN)、Chord(Chord project)、Pastry(Pastry (DHT)),以及 Tapestry (DHT)(Tapestry (DHT))皆同時於2001年發表。從那時開始,相關的研究便一直十分活躍。在學術領域以外,分散式雜湊表技術已經被應用在BitTorrent及CoralCDN(Coral Content Distribution Network)等。
結構
分散式雜湊表的結構可以分成幾個主要的元件。其基礎是一個抽象的關鍵值空間(keyspace),例如說所有160位元長的字元串集合。關鍵值空間分割(keyspace partitioning)將關鍵值空間分割成數個,並指定到在此系統的節點中。而延展網路則連接這些節點,並讓他們能夠藉由在關鍵值空間內的任一值找到擁有該值的節點。
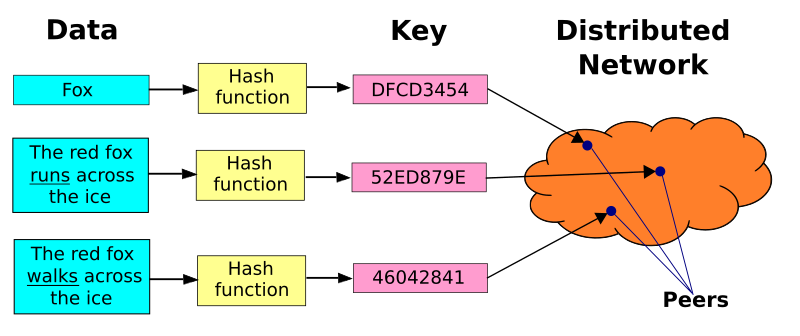
當這些元件都準備好後,一般使用分散式雜湊表來儲存與讀取的方式如下所述。假設關鍵值空間是一個160位元長的字元串集合。為了在分散式雜湊表中儲存一個檔案,名稱為 filename 且內容為 data,我們計算出 filename 的 SHA1 雜湊值——一個160位元的關鍵值 k——並將訊息 put(k,data) 送給分散式雜湊表中的任意參與節點。此訊息在延展網路中被轉送,直到抵達在關鍵值空間分割中被指定負責儲存關鍵值 k 的節點。而 (k,data) 即儲存在該節點。其他的節點只需要重新計算 filename 的雜湊值 k,然後送出訊息 get(k) 給分散式雜湊表中的任意參與節點,以此來找與 k 相關的資料。此訊息也會在延展網路中被轉送到負責儲存 k 的節點。而此節點則會負責傳回儲存的資料 data。
以下分別描述關鍵值空間分割及延展網路的基本概念。這些概念在大多數的分散式雜湊表實作中是相同的,但設計的細節部份則大多不同。
關鍵值空間分割
大多數的分散式雜湊表使用某些穩定雜湊(consistent hashing)方法來將關鍵值對應到節點。此方法使用了一個函數 δ(k1,k2) 來定義一個抽象的概念:從關鍵值k1 到 k2 的距離。每個節點被指定了一個關鍵值,稱為ID。ID 為 i 的節點擁有根據函數 δ 計算,最接近 i 的所有關鍵值。
例:Chord 分散式雜湊表實作將關鍵值視為一個圓上的點,而 δ(k1,k2) 則是沿著圓順時鐘地從 k1 走到 k2 的距離。結果,圓形的關鍵值空間就被切成連續的圓弧段,而每段的端點都是節點的ID。如果 i1 與 i2 是鄰近的 ID,則 ID 為 i2 的節點擁有落在 i1 及 i2 之間的所有關鍵值。
穩定雜湊擁有一個基本的性質:增加或移除節點只改變鄰近ID的節點所擁有的關鍵值集合,而其他節點的則不會被改變。對比於傳統的雜湊表,若增加或移 除一個位置,則整個關鍵值空間就必須重新對應。由於擁有資料的改變通常會導致資料從分散式雜湊表中的一個節點被搬到另一個節點,而這是非常浪費頻寬的,因 此若要有效率地支援大量密集的節點增加或離開的動作,這種重新配置的行為必須盡量減少。
延展網路
每個節點保有一些到其他節點(它的鄰居)的連結。將這些連結總合起來就形成延展網路。而這些連結是使用一個結構性的方式來挑選的,稱為網路拓樸。
所有的分散式雜湊表實作拓樸有某些基本的性質:對於任一關鍵值 k,某個節點要不就擁有 k,要不就擁有一個連結能連結到距離較接近 k 的節點。因此使用以下的貪心演算法即可容易地將訊息轉送到擁有關鍵值 k 的節點:在每次執行時,將訊息轉送到 ID 較接近 k 的鄰近節點。若沒有這樣的節點,那我們一定抵達了最接近 k 的節點,也就是擁有 k 的節點。這樣的轉送方法有時被稱為「基於關鍵值的轉送方法」。
除了基本的轉送正確性之外,拓樸中另有兩個關鍵的限制:其一為保證任何的轉送路徑長度必須盡量短,因而請求能快速地被完成;其二為任一節點的鄰近節點數目(又稱最大節點度(Degree (graph theory)))必須盡量少,因此維護的花費不會過多。當然,轉送長度越短,則最大節點度越大。以下列出常見的最大節點度及轉送長度(n 為分散式雜湊表中的節點數)
- 最大節點度 O(1),轉送長度 O(logn)
- 最大節點度 O(logn),轉送長度 O(logn / loglogn)
- 最大節點度 O(logn),轉送長度 O(logn)
- 最大節點度 O(n1 / 2),轉送長度 O(1)
第三個選擇最為常見。雖然他在最大節點度與轉送長度的取捨中並不是最佳的選擇,但這樣的拓樸允許較為有彈性地選擇鄰近節點。許多分散式雜湊表實作利用這種彈性來選擇延遲較低的鄰近節點。
最大的轉送長度與直徑有關:最遠的兩節點之間的最短距離。無疑地,網路的最大轉送長度至少要與它的直徑一樣長,因而拓樸也被最大節點度與直徑的取捨限制住,而這在圖論中是基本的性質。因為貪婪演算法(Greed Method)可能找不到最短路徑,因此轉送長度可能比直徑長。
範例
分散式雜湊表實作與協定
- Bamboo
- Bunshin
- 內容可定址網路 (Content Addressable Network)
- Chord
- DKS系統
- Kademlia
- Leopard
- MACE
- Pastry
- P-Grid
- Tapestry
Kademlia 網路的詳細解釋
基本上,Kademlia不是一個網路,是一個很熱門的技術,通稱為DHT (Distributed Hash Table 分散式雜湊表)。Kademlia 是個 Petar Maymounkov 與 David Mazières 所設計的點對點 (P2P) 重疊網路, 以達成非集中式的點對點 (P2P) 電腦網路。它規制了網路的結構及規範了節點間的通訊和交換資訊的方式。Kademlia 節點間使用傳輸通訊協定UDP溝通。Kademlia 節點藉以實作分散式雜湊表 (DHT,distributed hash table) 以儲存資料。透過既有的區域網/廣域網( LAN/WAN) (如同網際網路),一個新的虛擬網路或是重疊網路被建立起來。每個網路節點都是以一組數字(「節點 ID」)來識別。這組數字不但做為識別之用,Kademlia 演算法還會用來做其他用途。
一個想要加入網路的節點需要先通過啟動。在這個階段,這個節點需要知道另一個已經在 Kademlia 網路內的節點之 IP 位址 (透過另一個使用者或儲存的清單取得)。如果啟動中的節點還不是網路的一部分,它便會計算一個尚未指定給其他節點的隨機 ID 編號。這個 ID 會一直使用到離開網路為止。
Kademlia 演算法是基於兩節點間的「距離」來計算。這個距離是以兩節點的 ID 進行異或運算,並將結果四捨五入至整數。這個「距離」跟實際的地理環境無關,而是標明 ID 範圍內的距離。因此一個德國的節點和一個澳洲的節點就有可能被稱為「鄰居」或「芳鄰」。
Kademlia 內的資訊都儲存在稱為「數值」的東西內,每個數值都連接著一個「金鑰」。當搜尋某個金鑰時,演算法會透過幾個步驟探整個網路一圈,每個步驟都會更接近要搜尋的金鑰,直到被連線的節點傳回數值,或找不到更近的節點。網路的 大小僅會稍微影響到進行搜尋時接觸到的節點數目:假如目前網路的使用者突然增為兩倍,那使用者節點大概只需要在搜尋時多查詢一個節點,而不是兩倍的節點 量。
非集中式的結構提供了更大的優勢,並很明顯地增加了對拒絕服務阻斷攻擊的抵抗。即使一整系列的節點被壅塞,也不會對網路可用度造成太多影響,最後網路會透過繞過這些「洞」而自我修復。
在檔案分享網路中的應用
Kademlia 被用來進行檔案分享。透過進行 Kademlia 關鍵字搜尋,任何人可以在檔案分享網路中尋找資料以下載東西。由於沒有任何中央伺服器儲存檔案列表的索引,因此這項工作是平均的由所有的客戶端擔當:擁有要分享的檔案枝節點,會先處理檔案的內容,並從內容計算出一組數字(雜湊), 這組數字將會在檔案分享網路中辨識這個檔案。雜湊與節點 ID 的長度必須相同。接著會搜尋幾個 ID 與雜湊相近、且節點內有儲存著自己 IP 位址的節點。搜尋的客戶端會使用 Kademlia 來搜尋網路上節點ID離自己最近距離的節點來取得檔案雜湊,然後會取得在該節點上的聯絡清單。 當節點聯入和聯出時,這份存儲在網路上的聯絡清單也將保持不變。因為內嵌的冗余存儲演算法,聯繫清單將複製在多個點上。
檔案雜湊通常都是由其它地方的特製網際網路鍵結來取得,或者被包含在來自其它來源中的索引檔中。
對檔案名稱的搜索是基於關鍵字來實現的。檔案名稱被分成幾個組成檔案名稱的單字。 每個關鍵字都會被雜湊, 並和相對的檔案名稱與檔案雜湊利用和檔案雜湊一樣的方式儲存到網路上。一個搜索者會選擇其中的一個關鍵字,聯繫上和關鍵字雜湊最相近的節點ID,然後取得 含有關鍵字的檔案名稱列。既然在檔案名稱列中的每個檔案名稱都附有自己的湊雜,那麼被選的檔案就可以由一般的方式取得。
kad 網絡是一種根本不需要服務器的架構,每個emule客戶端負責處理一小部分search和source finding的工作。分配工作的原理是基於客戶端的唯一id和search或者source的hash之間的匹配來決定。比如說 LordOfRing1.avi這個文件由用戶abc來負責(通過文件的hash決定),則任何用戶共享這個文件的時候都會告訴用戶abc我有這個文件, 其他用戶去下載這個文件的時候也會詢問abc,abc告訴他們誰有這個文件,source finding就完成了。search的方法也差不多,每個人負責一個keyword。
至於如何找到用戶abc則是通過一種將用戶 id異或的方式,兩個id的二進制異或值決定他們之間的邏輯距離,比如1100距離1101要比距離1001近。當一個喲用戶加入kad後,首先通過一個 已知的用戶找到一批用戶的id和ip:port。當此用戶A要尋找某特定用戶x時,A先詢問幾個已知的邏輯距離X較近的用戶,如x1,x2,x3,x1, x2,x3會告訴A他們知道的更加近的用戶的id,ip和port,一次類推,A最終就能找到X。尋找的次數應該在logN數量級,N是總人數。
資料來源
分散式雜湊表 - Wikipedia
Kademlia - Wikipedia
zupi
yuchin